Mailing lists and newsgroups are havens in the choppy seas of technological adventure. Many computer users would never experiment with an cutting-edge system such as GNU/Linux or Ajax without the comfort of knowing they can find help from online forums. And even the most staid computer user will sneak into one of these venues to post the error message that was left behind as the sole indication of the pique that caused his faithful old Office program to turn up its nose and refuse to start.
In August 2006 I published some research concerning how mailing lists answer technical questions. I had conducted a modest experiment, analyzing the messages posted on 28 threads divided between two mailing lists devoted to Linux. My results included the following:
A high percentage of questions never get resolved, and many never even receive a response from anyone on the list.
List members, while generous with their time, tend to give up quickly: if the first couple messages fail to solve the problem, they rarely take the time to explore it in depth.
Suspecting that some of my observations may be specific to Linux-oriented lists, I decided to perform identical research on two newsgroups devoted to languages of which I had some knowledge: Perl and Ruby on Rails. These environments are much more focused than Linux, and therefore should provide less recalcitrant challenges to end-users and experts alike. Just think of the size of a typical Perl or Rails installation in comparison to a full Linux distribution with a windowing system and multiple background processes. Furthermore, Perl and Rails users rarely run into the hardware problems that are endemic to operating systems, and don't have to deal much with the quirks of external programs that range from DHCP address leasing to sound players, which is where operating system users expend most of their configuration effort.
An analysis of 14 Perl threads and 14 Rails threads confirmed the conclusions from my first experiment. The new experiment also raised interesting new questions about how to manage the complicated process of conveying expert knowledge to information-hungry newbies. There was clear evidence that the Rails list was not meeting the needs of many Rails users, who come to Rails with insufficient prior understanding of its way of thinking.
This second, independent experiment reinforced my conviction that:
Although mailing lists and newsgroups provide valuable support, a large percentage of questioners don't get the information they ask for.
Many users have inadequate background knowledge, a condition that cannot be addressed on the mailing list and that leads to frustration for both the questioners and those trying to help them.
Mailing lists could be better integrated with the more formal documentation sources offered by projects, such as Frequently Asked Questions lists and wikis.
Users need better search tools and ways to find relevant documentation, so they don't depend so much on questions on mailing lists.
Some of these issues have been explored by earlier articles in this series. This article summarizes the new data and its implications.
My second experiment was essentially the same as the one reported in my earlier article. I chose 14 threads at random from postings to comp.lang.perl.misc over the past few months, and another 14 from the Ruby on Rails: Talk list. (Both are hosted on Google Groups.) I chose only threads that began with requests for help with specific, clearly delimited problems, not general inquiries such as "How do I get started on Rails?"
My primary concern was the effectiveness of each thread, determinedly fundamentally by whether or not the user solved his problem. A secondary consideration was how long the answer took to emerge.
I then assessed the amount of noise on the thread, judging whether each posting contributed to the answer or distracted the readers from the task.
People curious about the methodology of the experiment can find details in my earlier article.
My research on Linux lists turned up a surprisingly high failure rate. Fully half of the 28 threads ended without solving the problem presented by the original posting. One-fourth of the questions were left hanging without a single response.
As explained at the beginning of this article, I expected the Perl and Rails lists to do much better because the subject matter was more constrained. But the Rails sample produced the exact same results as the Fedora and Ubuntu lists: 7 requests solved and 7 unsolved. Perl sample solved 9 of the 14 requests and left 5 unsolved, which is an improvement but still suggests that a lot of people go away frustrated.
I attribute the lower success rate on the Rails list to its high volume of traffic and to the flood of technically unsophisticated coders who bringing inadequate backgrounds to the difficult class of model-view-controller projects.
The high traffic volume, I surmise, is why many legitimate and apparently well-phrased questions go unanswered. The experts on the list just don't have time to check every post.
The bigger problem is the number of unsophisticated Rails users. I believe the quality of answers on the Rails list is just as high as on the Perl list, but the questioners lack the background to use the information--to take the ball and run with it.
Informal inspection suggests that there is a larger percentage of Rails newbies on the Rails list than Perl newbies on the Perl list. (Still, the Perl list is not all seasoned Perl coders; a number of new users post questions there.) The readers' experience with each list's particular technology is not the most salient factor, though. More important, I think, is that Perl list members tend to start with a computing background more suited to the task they take on, whether that be web application development, system administration, or data crunching.
Rails has been overhyped as a quick and easy way to put up web pages. Rails is great for people prepared to handle the task of designing an MVC system. But it has its challenges: unintuitive defaults, somewhat fussy requirements concerning the location of each declaration, and specialized syntax for representing operations common to MVC applications. Too many web designers and content providers without much computer background are rushing to Rails in the expectation that within a few days they will have a beautiful and robust interactive web site. The process is actually quite a bit more complicated.
Although the number of unsolved problems is somewhat disappointing, we still have to be impressed that so many people spend time answering strangers' questions, a phenomenon I explore in the recent article Why Do People Write Free Documentation? Results of a Survey.
And sometimes results come fast, in less than an hour. But overall, posting to a mailing probably brings an answer more slowly than documentation, if the person with a question has access to documentation and knows how to search it for information. (Many answers on mailing lists consist of pointers to Frequently Asked Questions lists or other web pages.)
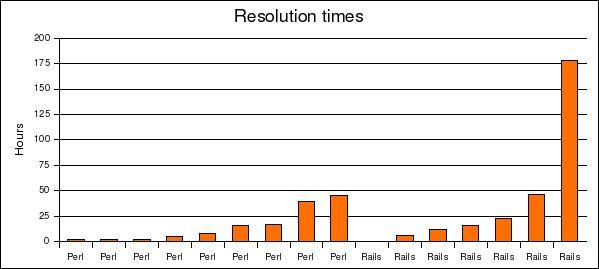
The median resolution time was 11.5 hours (slightly under 8 for Perl, over 16 for Rails, and about 10.5 for the two Linux lists). Users would find answers much more quickly if they could learn it from documentation, a behavior change that probably requires clearer documentation as well as more educated users.
Table 1 shows the minimum, median, and maximum resolution times for the Perl and Rails mailing lists, separately. It also compares the two language lists to the two Linux lists, and shows total results. Figure 1 shows the resolution times for each thread on the Perl and Rails lists. Yes, one thread on the Rails list went on more than a week!
| Minimum | Median | Maximum | |
|---|---|---|---|
| Perl | 2 hours | 8 hours | 1 day, 21 hours |
| Rails | 0.5 hours | 16 hours | 7 days, 10 hours |
| Both operating systems | 0.1 hours | 10.5 hours | 2 days, 10 hours |
| Both languages | 0.5 hours | 13.5 hours | 7 days, 10 hours |
| All lists | 0.1 hours | 11.5 hours | 7 days, 10 hours |
In addition to measuring the time it took to resolve a message, my data collection tracked the number of messages on each thread. I originally thought this was a measure of efficiency; in other words, I assumed that a thread with only 2 messages would be better than a thread with 20 messages, so long as both resolved the original question.
Now I realize that this assumption is unwarranted. Some problems are particularly complicated and require a lot of help, such as requests by respondents for further data from the original poster.
In fact, a high number of messages--so long as they are helpful--may be a tribute to the dedication of the list members. They care enough about supporting language users to keep posting new advice over until the problem is solved, the original questioner stops posting, or everyone has run out of ideas.
Figure 2 shows the number of messages on each thread, grouped by mailing list. The threads marked with check signs were resolved (that is, the questioner got a satisfactory answer); threads without check signs were unresolved. Although Perl list members tended to post more than Rails list members on each thread, the variation on both lists was so great that I wouldn't draw any conclusions from that statistic.
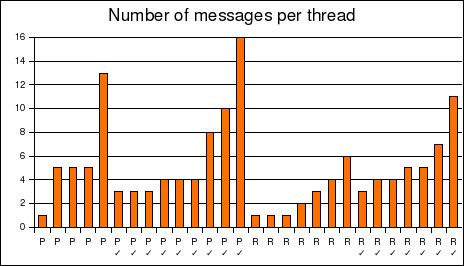
As you can see, there is not much difference between resolved and unresolved threads; list members tended to give up quickly if they could not answer a question. Perl posters stayed a little longer on the unresolved threads, and Rails posters on the resolved threads.
To be fair, the person posting a question often dropped out and failed to answer reasonable requests from other list members for more information. I believe, again, that the original poster in these circumstances lacked the computing knowledge and breadth of experience to handle the task he or she had taken on, and that the questions posed on the list brought him or her to that realization. Unfortunately, we will never know how many of these posters took a step back and sought out documentation that could bolster their competency, as opposed to simply dropping their projects.
We know that many messages on technical lists deal with list behavior instead of direct technical questions. Useful meta-information is provided by messages about what documents to read before posting, what information to post, and the proper way to structure messages (bottom-posting instead of top-posting, for instance). These could also be considered a way to build community, along with messages about upcoming conferences, books on the topic, famous members of the community, legal issues, and general banter. And we must not forget community-building messages along the lines of "Your lack of respect for this list's contributors is shown by posting such a stupid question" and "Well, you're showing a lack of respect to newbies; postings like yours will destroy all interest in the topic."
Luckily, most of the messages I found of the nastier sort (which were on the Perl list; the Rails list was remarkably free of attitude problems) were sequestered into threads with titles such as "ignorance and intolerance in computing communities" or "Microsoft Hatred FAQ," allowing busy readers to ignore them--which I did for the purposes of this article.
The Rails list contains a fair amount of unsolicited commercial email, an indication of the list's popularity and the number of new people pouring continuously onto it. Spammers depend not on the wisdom of crowds, but on the gullibility of its least experienced members.
I have found no spam on the Perl list. But the attitude problems leaked into the threads I examined concerning technical topics, and led me to classify several messages as irrelevant. Basically, I considered a message irrelevant if it contained no useful information, or just commented on some aspect of the discussion or the list without attempting to answer the question that began the thread. Some of these, as I've indicated, may be useful meta-information and may build (or alternatively tear down) a sense of community. But they also take time away from solving the problem.
I also reserved a category for unhelpful messages, which had to meet a much more stringent criterion. An unhelpful message was one that claimed to be offering a solution while actually providing wrong information. For instance, when someone posted a script with the cheerful assurance that "It works for me" and then had to admit (in response to a challenge from another list member) that it didn't work, I classified his first message as unhelpful.
On another thread, someone asked for guidance with a specific technique and was answered with the statement, "This is called AJAX." As a flippant and dismissive generalization, it would have marked the message merely as irrelevant. But in fact, the technique turned out to be fully client-side, whereas AJAX involves client-server interaction, so I classified the message as unhelpful.
The vast majority of messages, luckily, are helpful: that is, they try to answer the question. Not all such messages suggest lines of inquiry that lead to the ultimate solution, but they are still helpful because they explore feasible actions that a user should try.
A fourth category, new messages, covered the original question that began each thread.
Figure 3 shows the percentage of messages that fell into each of the four categories. I compared Perl, Rails, both language lists in combination (Perl and Rails), the two lists on the Linux operating system, and all four lists in combination (Total).
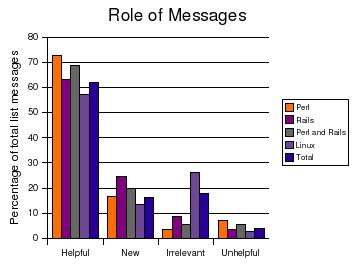
Although the Perl list had an unusually high percentage of unhelpful messages, for which I can't find a reason, the attitude problem did not turn up often enough to generate a high percentage of irrelevant messages.
What's really interesting is the high percentage of irrelevant messages on the Linux lists. As my earlier article reported, some threads were elongated by long debates about the Linux community and the right way to use the lists. These lists also contains many separate threads--not considered in my studies--related to policy, legal, and other non-technical topics.
I believe this concentration on non-technical topics reflects the odd position of Linux in our society. Linux stands for all the issues of social equity summed up in the term "digital divide," for attitudes toward Microsoft and anti-trust actions, and for hopes of general social transformation through the voluntary collaboration of unrelated individuals on open source projects. Although the vast majority of Linux users adopt it for practical reasons, the mere possession of Linux--like a gun or a family SUV--has become a political statement.
Furthermore, while Linux is entirely mainstream, and its adoption by large organizations is irreversible, it remains a vulnerable and beleaguered object. Its users are routinely reminded of patent and copyright issues brought by SCO and Microsoft, "anti-circumvention" laws that push underground the creation and distribution of some of its most popular software, and the possibility that its license (the GNU General Public License, version 2) will not suffice to keep technical advances from slipping into private hands.
The awareness of these issues, I believe, along with tension concerning their future resolution, causes the high volume of non-technical postings on the Linux lists. In contrast, although Perl and Rails are open source, they are used in conflict-free environments and rarely discussed in relation to social policy.
Building on earlier articles (listed at the end of this article) in this series about community documentation, I'll try to draw some conclusions from this article's research to improve the experience of computer users who go online in search of information.
The combination of my two research projects on mailing lists provides pretty clear evidence that mailing lists fall short for many users. A surprisingly large percentage don't get answers to their questions. Although answers for others may come within several hours, the answers often consist of pointers to documentation that one would wish the user could find on his own. Had the user known the answer was available in some document, he could have found it some 90% more quickly and avoided bothering other people.
Thus, the results call for better organization of documents, and more pathways that lead new users into the documents. I have made some specific suggestions in earlier articles.
Most disturbing is the apparent unfitness of many aspiring users, particularly those starting Rails projects. Jumping into a complex programming environment without related computing experience, and a clear mental model of the system, leads only to frustration and an immense waste of time.
To search for improvements to the system, we can look to the one work universally cited as the way into Rails: the book Agile Web Development with Rails by Dave Thomas, David Heinemeier Hansson, et al. The Perl community has certain canonical books too (notably the Camel, Programming Perl, which was co-authored by Larry Wall, the creator of Perl), but most of these, including the Camel, are not aimed at an introductory level. Perl lacks a single, well-trodden "path to success" as Rails has.
Agile Web Development with Rails succeeds, in my opinion, because it fits the pieces of a complex system together for the new user in a clever manner. Although the book builds a pretty full-featured system as an example, the authors do not allow the immediate mechanics of creating the example to get in the way of explaining the deeper significance of each step in the process: the impact of each declaration or statement on the entire system.
Every good tutorial suggests why and when to use various techniques. But the key to readers developing a mental model of a system--and therefore to extend their initial knowledge to handle new situations--is for the readers also to understand the effects their actions have on the larger system. For instance, they must not just understand they can solve a problem by adding a certain declaration in a certain place, but understand that this declaration creates an object with a certain persistence that is queried by other parts of the system at certain times. Only such knowledge permits them to do creative things and anticipate results.
Agile Web Development with Rails conveys much of the basics of Rails on this level. But reading it does not guarantee that users can cope with the range of Rails tools and related technologies. No book can inculcate readers with the sophistication required to apply its tools to the idiosyncratic needs of all new projects; some insights can come only from experience. In addition, Rails brings in too many related technologies for any one book to cover.
This analysis suggests two areas for improvement in documentation and mailing lists:
New documents on subsidiary technologies can help fill in users' understanding by adopting some of the techniques of the best documentation: explaining the structure of the system into which the technology fits, and elevating the reader's ability to judge the impacts of using the technology. Such improvements to documentation may well require professional help.
Experts on mailing lists can guide users through projects in ways that stretch the users' mental capacities, rather than just provide raw information or pointers to documents. Abstract information has limited value for most users, and practical experimentation comes up against roadblocks in the users' understanding. But abstract information and practical experimentation together are a powerful learning tool. Mailing lists should evolve to support the combination, which entails much more intimate and trusting collaboration between experts and new users.
Many experts wish that every user would familiarize herself with the full range of available documentation before posing a question on a mailing list. But such expectations are unreasonable. Reasonably mature projects have too much documentation for busy people to read, but even more significant is the difficulty of finding and searching through that documentation. Most inhibitory is the difficulty many users have recognizing that the documentation applies to their system. In other words, they could spend a week going over the documentation and have the answer pass right by them.
That is why users need background that gives them the mental models that fit pieces of the system together and give it meaning. To that end, they could also use guidance from expert members of mailing lists--not just pointers to documentation, but training in how to read it. Experts could hone newbies' skills with tips such as, "Look for sections about these topics..." or, "Your question is really about..."
The wealth of knowledge available on technical mailing lists is impressive, and experts spend a good deal of time on these lists. We should create both technological aids and social expectations that increase the value of the time spent there.
(Thanks to a generous volunteer, Paintings blog, this article is also available in a Russian translation.)
Splitting Books Open: Trends in Traditional and Online Technical Documentation (September 23, 2004)
Rethinking Community Documentation (July 6, 2006)
Do-It-Yourself Documentation? Research Into the Effectiveness of Mailing Lists (August 19, 2006)
Why Do People Write Free Documentation? Results of a Survey (June 14, 2007)
The data for this study is available in the form of results of database queries.
Andy Oram
Editor, O’Reilly Media
Home page

This work is licensed under a Creative Commons Attribution 4.0 International License.